Any processor instruction has multiple stages to its operation.
Each one of these stages takes a single CPU cycle to complete.
These stages are Instruction fetch, Instruction decode, Execute, Memory access, and Writeback.

Contents
Historical In Order Processors
In early computers, the CPU didnt use an instruction pipeline.
In these CPUs, each single-cycle operation needed to happen for every instruction.
In a subscalar processor with no pipeline, each part of each instruction is executed in order.
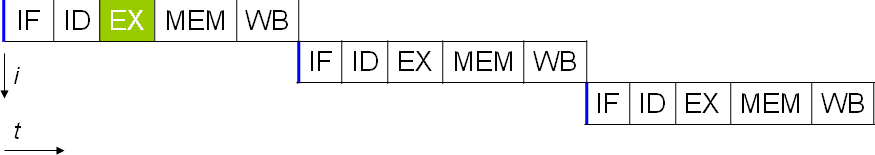
The problem is the cache miss.
The CPU stores data it is actively processing in the register.
This can be accessed with a one-cycle latency.
The problem is that the register is tiny because its built into the processor core.
The CPU must go to the larger but slower L1 cache if the data hasnt already been loaded.
If its not there, it must go to the larger and slower L2 cache again.
The next step is the L3 cache; the final option is the system RAM.
Each of these options takes more and more CPU cycles to check.
All the while, nothing else can happen on the computer.
Technically, this can be alleviated somewhat by having two independent cores.
Nothing, however, stops them both from doing the same thing, potentially simultaneously.
So going down the multi-core route doesnt fix this.
The Classic RISC Pipeline
RISC stands for Reduced Instruction Set Computer.
Its a style of processor design that optimizes performance by making decoding each instruction easier.
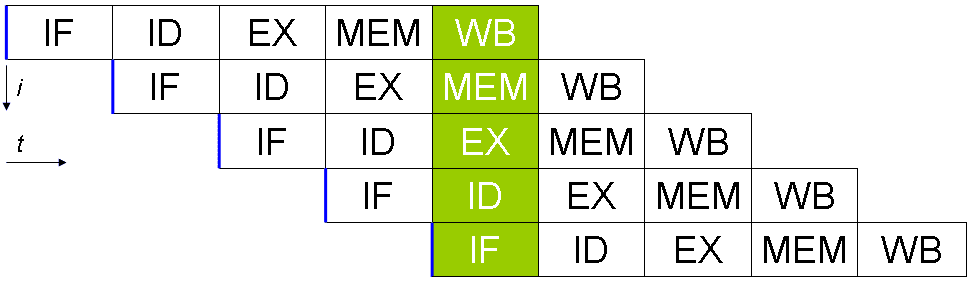
The classic RISC design includes an instruction pipeline.
Of course, you cant run all five stages of one instruction in a cycle.
But you might queue up five consecutive instructions with an offset of one stage each.
This way, a new instruction can be completed each clock cycle.
Offering a potential 5x performance increase for a relatively low rise in core complexity.
In a scalar pipelined processor, each stage of an instructions execution can be performed once per clock cycle.
This allows a maximum throughput of one completed instruction per cycle.
Of course, there are still potential issues.
It also introduces a new problem.
What if one instruction relies on the output of the previous instruction?
These problems are independently solved with an advanced dispatcher.
Conclusion
A pipeline allows for all of the processors distinct capabilities to be used in every cycle.
It does this by running different stages of different instructions simultaneously.
This doesnt even add much complexity to the CPU design.
It also paves the way to allow more than one instruction to perform a single stage per cycle.
